
Path: blob/main/06. Databases and SQL for Data Science with Python/05. Course Assignment/Notebook for Peer Assignment.ipynb
8948 views
Assignment: Notebook for Peer Assignment
Introduction
Using this Python notebook you will:
Understand three Chicago datasets
Load the three datasets into three tables in a Db2 database
Execute SQL queries to answer assignment questions
Understand the datasets
To complete the assignment problems in this notebook you will be using three datasets that are available on the city of Chicago's Data Portal:
1. Socioeconomic Indicators in Chicago
This dataset contains a selection of six socioeconomic indicators of public health significance and a “hardship index,” for each Chicago community area, for the years 2008 – 2012.
A detailed description of this dataset and the original dataset can be obtained from the Chicago Data Portal at: https://data.cityofchicago.org/Health-Human-Services/Census-Data-Selected-socioeconomic-indicators-in-C/kn9c-c2s2
2. Chicago Public Schools
This dataset shows all school level performance data used to create CPS School Report Cards for the 2011-2012 school year. This dataset is provided by the city of Chicago's Data Portal.
A detailed description of this dataset and the original dataset can be obtained from the Chicago Data Portal at: https://data.cityofchicago.org/Education/Chicago-Public-Schools-Progress-Report-Cards-2011-/9xs2-f89t
3. Chicago Crime Data
This dataset reflects reported incidents of crime (with the exception of murders where data exists for each victim) that occurred in the City of Chicago from 2001 to present, minus the most recent seven days.
A detailed description of this dataset and the original dataset can be obtained from the Chicago Data Portal at: https://data.cityofchicago.org/Public-Safety/Crimes-2001-to-present/ijzp-q8t2
Download the datasets
This assignment requires you to have these three tables populated with a subset of the whole datasets.
In many cases the dataset to be analyzed is available as a .CSV (comma separated values) file, perhaps on the internet. Click on the links below to download and save the datasets (.CSV files):
NOTE: Ensure you have downloaded the datasets using the links above instead of directly from the Chicago Data Portal. The versions linked here are subsets of the original datasets and have some of the column names modified to be more database friendly which will make it easier to complete this assignment.
Store the datasets in database tables
To analyze the data using SQL, it first needs to be stored in the database.
While it is easier to read the dataset into a Pandas dataframe and then PERSIST it into the database as we saw in Week 3 Lab 3, it results in mapping to default datatypes which may not be optimal for SQL querying. For example a long textual field may map to a CLOB instead of a VARCHAR.
Therefore, it is highly recommended to manually load the table using the database console LOAD tool, as indicated in Week 2 Lab 1 Part II. The only difference with that lab is that in Step 5 of the instructions you will need to click on create "(+) New Table" and specify the name of the table you want to create and then click "Next".
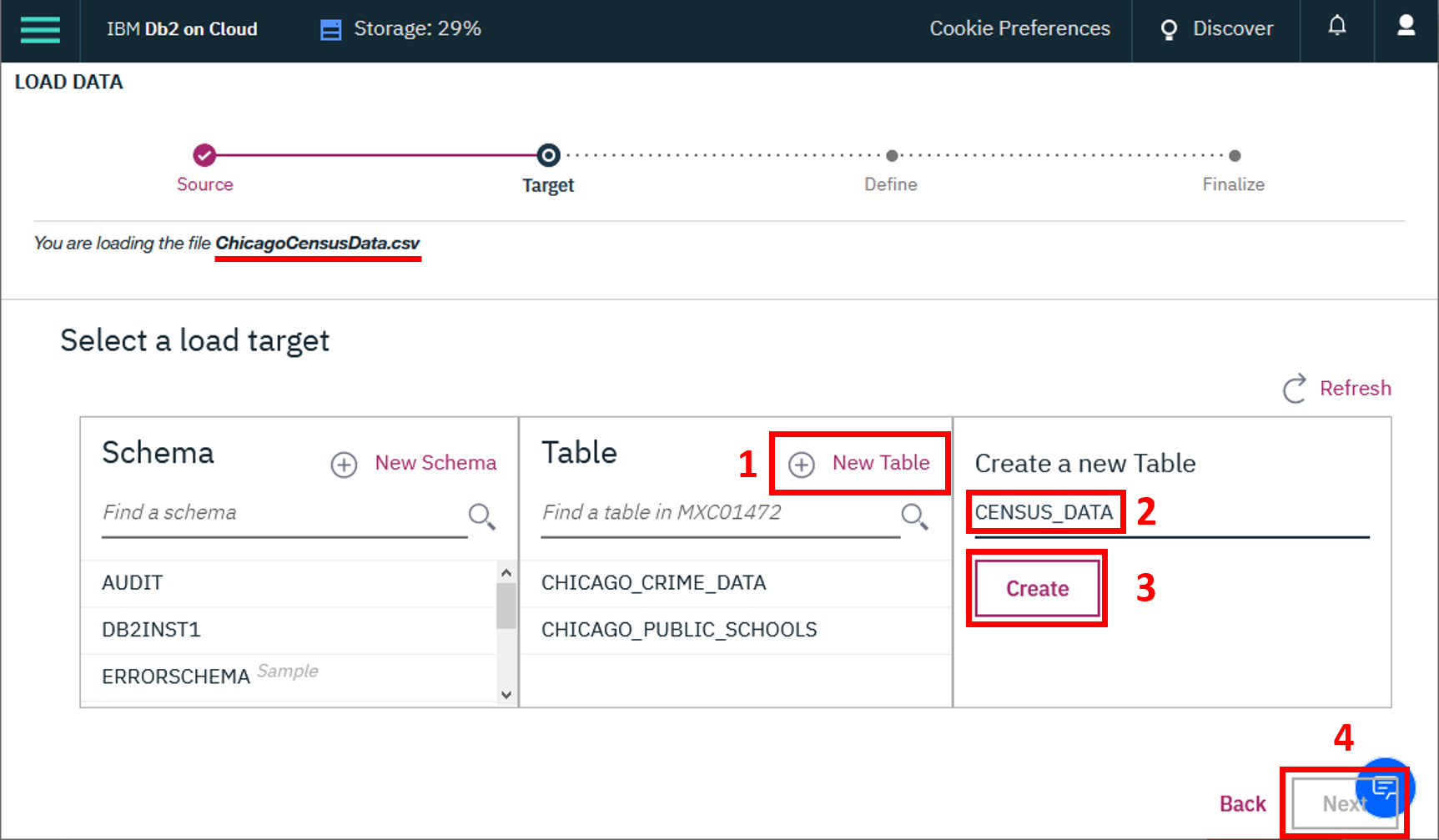
Now open the Db2 console, open the LOAD tool, Select / Drag the .CSV file for the first dataset, Next create a New Table, and then follow the steps on-screen instructions to load the data. Name the new tables as follows:
CENSUS_DATA
CHICAGO_PUBLIC_SCHOOLS
CHICAGO_CRIME_DATA
Connect to the database
Let us first load the SQL extension and establish a connection with the database
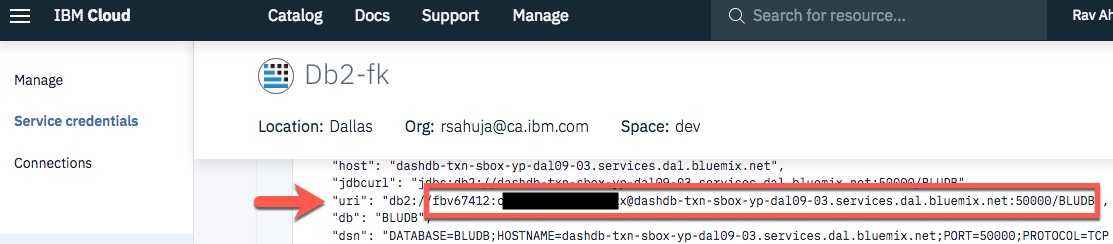
In the next cell enter your db2 connection string. Recall you created Service Credentials for your Db2 instance in first lab in Week 3. From the uri field of your Db2 service credentials copy everything after db2:// (except the double quote at the end) and paste it in the cell below after ibm_db_sa://
Problems
Now write and execute SQL queries to solve assignment problems